



Next: The plot() Command
Up: Details
Previous: Details
Contents
The summary() command gives measures of the balance between
the treated and control groups in the full (original) data set, and
then in the matched data set. If the matching worked well, the
measures of balance should be smaller in the matched data set (smaller
values of the measures indicate better balance).
The summary() output for subclassification is the same as
that for other types of matching, except that the balance statistics
are shown separately for each subclass, and the overall balance in the
matched samples is calculated by aggregating across the subclasses,
where each subclass is weighted by the number of units in the
subclass. For exact matching, the covariate values within each
subclass are guaranteed to be the same, and so the measures of balance
are not output for exact matching; only the sample sizes in each
subclass are shown.
- Balance statistics: The statistics the summary()
command provides include means, the original control group standard deviation (where applicable),
mean differences, standardized mean
differences, and (median, mean and maximum) Quantile-Quantile (Q-Q)
plot differences. In addition, the summary() command will
report (a) the matched call, (b) how many units were matched,
unmatched, or discarded due to the discard option
(described below), and (c) the percent improvement in balance for
each of the balance measures, defined as
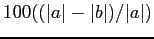 , where
, where
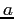 is the balance before and
is the balance before and 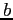 is the balance after matching.
For each set of units (original and matched data sets, with weights
used as appropriate in the matched data sets), the
following statistics are provided:
is the balance after matching.
For each set of units (original and matched data sets, with weights
used as appropriate in the matched data sets), the
following statistics are provided:
- ``Means Treated'' and ``Means Control'' show the weighted
means in the treated and control groups
- ``SD Control" is the standard deviation calculated in the control group (where applicable)
- ``Mean Diff'' is the difference in means between the groups
- The final three columns of the summary output give summary
statistics of a Q-Q plot (see below for more information on these
plots). Those columns give the median, mean, and maximum distance
between the two empirical quantile functions (treated and control
groups). Values greater than 0 indicate deviations between the
groups in some part of the empirical distributions. The plots of
the two empirical quantile functions themselves, described below,
can provide further insight into which part of the covariate
distribution has differences between the two groups.
- Additional options: Three options to the summary()
command can also help with assessing balance and respecifying the
propensity score model, as necessary. First, the interactions
= TRUE option with summary() shows the balance of all
squares and interactions of the covariates used in the matching
procedure. Large differences in higher order interactions usually
are a good indication that the propensity score model (the distance measure) needs to be
respecified. Similarly, the addlvariables option with summary() will provide balance measures on additional variables
not included in the original matching procedure. If a variable (or
interaction of variables) not included in the original propensity score model
has large imbalances in the matched groups, including that
variable in the next model specification may improve the resulting
balance on that variable. Because the outcome variable is not used
in the matching procedure, a variety of matching methods can be
tried, and the one that leads to the best resulting balance chosen. Finally,
the standardize = TRUE option will print out standardized versions of the
balance measures, where the mean difference is standardized (divided) by the standard deviation
in the original treated group.
Next: The plot() Command
Up: Details
Previous: Details
Contents
RBuild autobuild user
2011-10-24