- formula
- An optional formula without a dependent variable that
is of class ``formula'' and that follows standard R
conventions for formulas, e.g.
~ x1 + x2. Allows you to
transform or otherwise re-specify combinations of the variables in
both data and cfact. To use this parameter, both
data and cfact must be coercable to data frames;
the variables of both data and cfact must be
labeled; and all variables appearing in formula must also
appear in both data and cfact. Otherwise, errors
are returned. The intercept is automatically dropped. Default is
NULL.
- data
- May take one of the following forms:
- A R model output object, such as the output from calls to
lm, glm, and zelig. Such an output
object must be a list. It must additionally have either a formula
or terms component and either a data or model component; if it
does not, an error is returned. Of the latter, whatif
first looks for data, which should contain either the original
data set supplied as part of the model call (as in glm)
or the name of this data set (as in zelig), which is
assumed to reside in the global environment. If data does not
exist, whatif then looks for model, which should
contain the model frame (as in lm). The intercept is
automatically dropped from the extracted observed covariate
data set if the original model included one.
- A
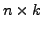 non-character (logical or numeric) matrix or data
frame of observed covariate data with
non-character (logical or numeric) matrix or data
frame of observed covariate data with 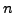 data points or
units and
data points or
units and 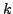 covariates. All desired variable transformations
and interaction terms should be included in this set of
covariates unless formula is alternatively used to
produce them. However, an intercept should not be. Such a matrix
may be obtained by passing model output (e.g., output from a call
to lm) to model.matrix and excluding the
intercept from the resulting matrix if one was fit. Note
that whatif will attempt to coerce data frames to their
internal numeric values. Hence, data frames should only contain
logical, numeric, and factor columns; character columns will lead
to an error being returned.
covariates. All desired variable transformations
and interaction terms should be included in this set of
covariates unless formula is alternatively used to
produce them. However, an intercept should not be. Such a matrix
may be obtained by passing model output (e.g., output from a call
to lm) to model.matrix and excluding the
intercept from the resulting matrix if one was fit. Note
that whatif will attempt to coerce data frames to their
internal numeric values. Hence, data frames should only contain
logical, numeric, and factor columns; character columns will lead
to an error being returned.
- A string. Either the complete path (including file name) of
the file containing the data or the path relative to your working
directory. This file should be a white space delimited text file.
If it contains a header, you must include a column of row names as
discussed in the help file for the R function
read.table. The data in the file should be as otherwise
described in (2).
Missing data is allowed and will be dealt with via the argument
missing. It should be flagged using R's
standard representation for missing data, NA.
- cfact
- A R object or a string. If a R object,
a
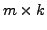 non-character matrix or data frame of
counterfactuals with
non-character matrix or data frame of
counterfactuals with 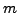 counterfactuals and the same
covariates (in the same order) as in data. However, if
formula is used to select a subset of the
covariates,
then cfact may contain either only these
counterfactuals and the same
covariates (in the same order) as in data. However, if
formula is used to select a subset of the
covariates,
then cfact may contain either only these 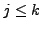 covariates or the complete set of
covariates. An intercept
should not be included as one of the covariates. It will be
automatically dropped from the counterfactuals generated by
Zelig if the original model contained one. Data frames
will again be coerced to their internal numeric values if possible.
If a string, either the complete path (including file name) of the
file containing the counterfactuals or the path relative to your
working directory. This file should be a white space delimited text
file. See the discussion under data for instructions on
dealing with a header. All counterfactuals should be fully
observed: if you supply counterfactuals with missing data, they will
be list-wise deleted and a warning message will be printed to the
screen.
covariates or the complete set of
covariates. An intercept
should not be included as one of the covariates. It will be
automatically dropped from the counterfactuals generated by
Zelig if the original model contained one. Data frames
will again be coerced to their internal numeric values if possible.
If a string, either the complete path (including file name) of the
file containing the counterfactuals or the path relative to your
working directory. This file should be a white space delimited text
file. See the discussion under data for instructions on
dealing with a header. All counterfactuals should be fully
observed: if you supply counterfactuals with missing data, they will
be list-wise deleted and a warning message will be printed to the
screen.
- range
- An optional numeric vector of length
, where
is
the number of covariates. Each element represents the range of the
corresponding covariate for use in calculating Gower distances. Use
this argument when covariate data do not represent the population of
interest, such as selection by stratification or experimental
manipulation. By default, the range of each covariate is calculated
from the data (the difference of its maximum and minimum values in
the sample), which is appropriate when a simple random sampling
design was used. To supply your own range for the
th covariate,
set the
th element of the vector equal to the desired range and
all other elements equal to NA. Default is NULL.
- freq
- An optional numeric vector of any positive length, the
elements of which comprise a set of distances. Used in calculating
cumulative frequency distributions for the distances of the data
points from each counterfactual. For each such distance and
counterfactual, the cumulative frequency is the fraction of observed
covariate data points with distance to the counterfactual less than
or equal to the supplied distance value. The default varies with
the distance measure used. When the Gower distance measure is
employed, frequencies are calculated for the sequence of Gower
distances from 0
to
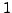 in increments of
in increments of 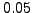 . When the Euclidian
distance measure is employed, frequencies are calculated for the
sequence of Euclidian distances from the minimum to the maximum
observed distances in twenty equal increments, all rounded to two
decimal places. Default is NULL.
. When the Euclidian
distance measure is employed, frequencies are calculated for the
sequence of Euclidian distances from the minimum to the maximum
observed distances in twenty equal increments, all rounded to two
decimal places. Default is NULL.
- nearby
- An optional scalar indicating which observed data
points are considered to be nearby (i.e., within `nearby' geometric
variances of) the counterfactuals. Used to calculate the summary
statistic returned by the function: the fraction of the observed
data nearby each counterfactual. By default, the geometric
variability of the covariate data is used. For example, setting
nearby to
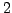 will identify the proportion of data points
within two geometric variances of a counterfactual. Default is 1.
will identify the proportion of data points
within two geometric variances of a counterfactual. Default is 1.
- distance
- An optional string indicating the distance measure to
employ. The choices are either "gower", Gower's
non-parametric distance measure (
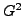 ), which is suitable for
both qualitative and quantitative data; or "euclidian",
(squared) Euclidian distance, which is only suitable for quantitative
data. The default is the former, "gower".
), which is suitable for
both qualitative and quantitative data; or "euclidian",
(squared) Euclidian distance, which is only suitable for quantitative
data. The default is the former, "gower".
- miss
- An optional string indicating the strategy for dealing
with missing data in the observed covariate data set.
whatif supports two possible missing data strategies:
"list", list-wise deletion of missing cases; and
"case", ignoring missing data case-by-case (pairwise
deletion). Note that if "case" is selected, observations
with missing values are still deleted listwise for the convex hull
test and for computing Euclidian distances, but pairwise deletion is
used in computing the Gower distances to maximally use available
information. The user is strongly encouraged to treat missing data
using specialized tools such as Amelia prior to feeding the data to
whatif. Default is "list".
- choice
- An optional string indicating which analyses to
undertake. The options are either "hull", only perform the convex hull
membership test; "distance", do not perform the convex
hull test but do everything else, such as calculating the distance between
each counterfactual and data point; or "both", undertake both the
convex hull test and the distance calculations (i.e., do everything).
Default is "both".
- return.inputs
- A Boolean; should the processed observed
covariate and counterfactual data matrices on which all
whatif computations are performed be returned? Processing
refers to internal whatif operations such as the subsetting
of covariates via formula, the deletion of cases with
missing values, and the coercion of data frames to numeric matrices.
Primarily intended for diagnostic purposes. If TRUE, these matrices
are returned as a list. Default is FALSE.
- return.distance
- A Boolean; should the matrix of distances
between each counterfactual and data point be returned? If
TRUE, this matrix is returned as part of the output; if
FALSE, it is not. Default is FALSE due to the large
size that this matrix may attain.
Gary King
2010-08-12